TLDR; I find some (minor) evidence that dependencies of R projects have become more numerous over time.
I have a theory that software projects in general and R projects in particular are getting more complex over time. This has several consequences as you’re well aware if you’ve tried for instance install.packages("somepackage") and seen the dependency installs fly by. The consequence I’m concerned with is the possibility that increasing install-complexity is a de-motivating factor in implementing reproducible workflows. As the number of dependencies increases, the more complex the task becomes of wrangling and tracking these for sharing and reproducibility purposes.
As a first attempt to investigate the potential for increasing install complexity over time, I analyzed the data archive of publications in the Journal of Open Source Software (JOSS).
I start by downloading this archive (available from the joss-analytics repo):
library(gh)
library(desc)
library(ggplot2)
suppressMessages(library(dplyr))joss_rds <- "data/joss_R.rds"
dir.create("data", showWarnings = FALSE)
# unlink(joss_rds)
if (!file.exists(joss_rds)) {
papers <- readRDS(gzcon(url(
"https://github.com/openjournals/joss-analytics/blob/gh-pages/joss_submission_analytics.rds?raw=true")))
dt <- dplyr::filter(papers, repo_language == "R")
saveRDS(dt, "data/joss_R.rds")
}
dt <- readRDS(joss_rds)Then I use the repo_url field in the JOSS archive to search for the DESCRIPTION files associated with submissions (and download them).
get_desc <- function(i, dt, path = "DESCRIPTION") {
# print(i)
out_path <- paste0("data/", "DESCRIPTION", "_", as.character(i))
if(!file.exists(out_path)) {
tryCatch({
tryCatch({
download.file(paste0(dt$repo_url[i], "/raw/master/DESCRIPTION"), path)
Sys.sleep(runif(1, max = 3))
file.copy(path, out_path)
Sys.sleep(runif(1, 2, 5))
}, error = function(e) {
download.file(paste0(dt$repo_url[i], "/raw/main/DESCRIPTION"), path)
Sys.sleep(runif(1, max = 3))
file.copy(path, out_path)
Sys.sleep(runif(1, 2, 5))
})
}, error = function(e) {
print(e)
})
}
}
lapply(seq_len(nrow(dt)), function(i) get_desc(i, dt))Next, I use the get_deps functionality of the desc R package to count the number of dependencies.
get_deps <- function(i) {
# print(i)
path <- paste0("data/", "DESCRIPTION", "_", as.character(i))
if(!file.exists(path)) {
return(i)
}
d <- desc::desc(file = path)
deps <- d$get_deps()
deps$pkg_name <- strsplit(dt$api_title[i], "\\:")[[1]][1]
deps <- dplyr::filter(deps, !grepl("R", package))
deps$i <- i
deps
}
deps <- lapply(seq_len(nrow(dt)), function(i) get_deps(i))Finally, I join the dependency counts with the original archive data to get the dates of publication for each entry.
n_deps <- unlist(lapply(deps, function(x) ifelse(is.null(nrow(x)), NA, nrow(x))))
pkg_names <- unlist(lapply(deps, function(x) substr(x["pkg_name"][[1]][1], 0, 17)))
res <- data.frame(pkg_name = pkg_names, n_dep = n_deps)
res <- res[seq_len(max(which(!is.na(res["n_dep"])))), ]
res_dt <- cbind(res, dt[seq_len(nrow(res)),])ggplot(res_dt, aes(published.date, n_dep)) +
geom_point() +
geom_smooth(method = "lm", se = TRUE) +
ylim(0, 50) +
labs(x = "", y = "# of listed dependencies") +
ggtitle(paste0("n = ", nrow(res_dt))) +
theme_classic() +
coord_fixed(28)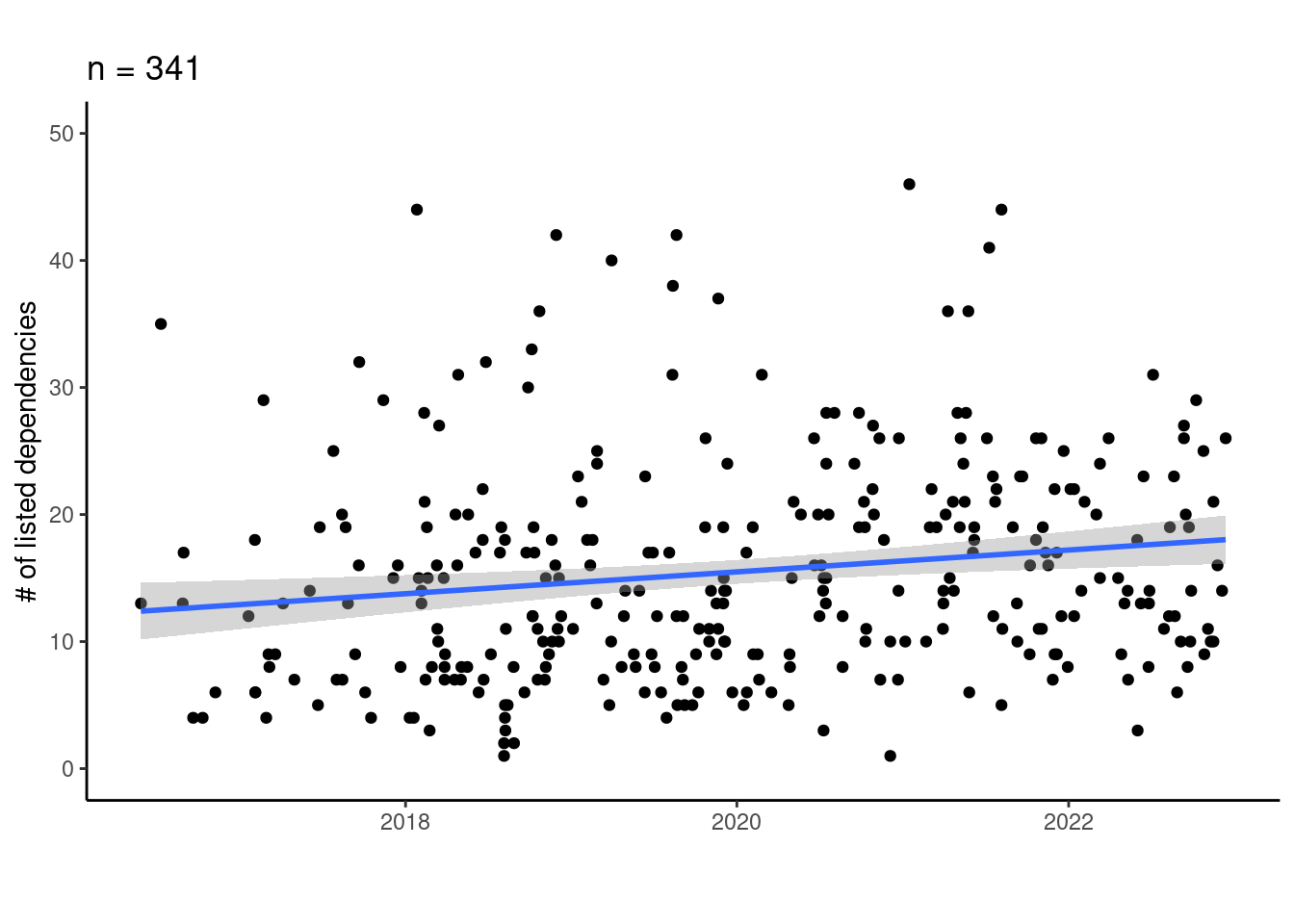
I find some evidence (albeit minor) for an increasing number of dependencies through time!
Some caveats:
JOSS authors are probably more experienced than a random analyst. Would this make dependencies more numerous?
Related to 1, JOSS submissions are software “products” not analysis products. Maybe the trends would be different for analysis products? I could see in the bad old days people using 4-5 packages for creating a simple plot whereas nowadays maybe more people are just using
ggplot2?This analysis was limited to JOSS submissions tagged as
R. Are there cultural reasons particular to the R community that would cause/influence this trend?